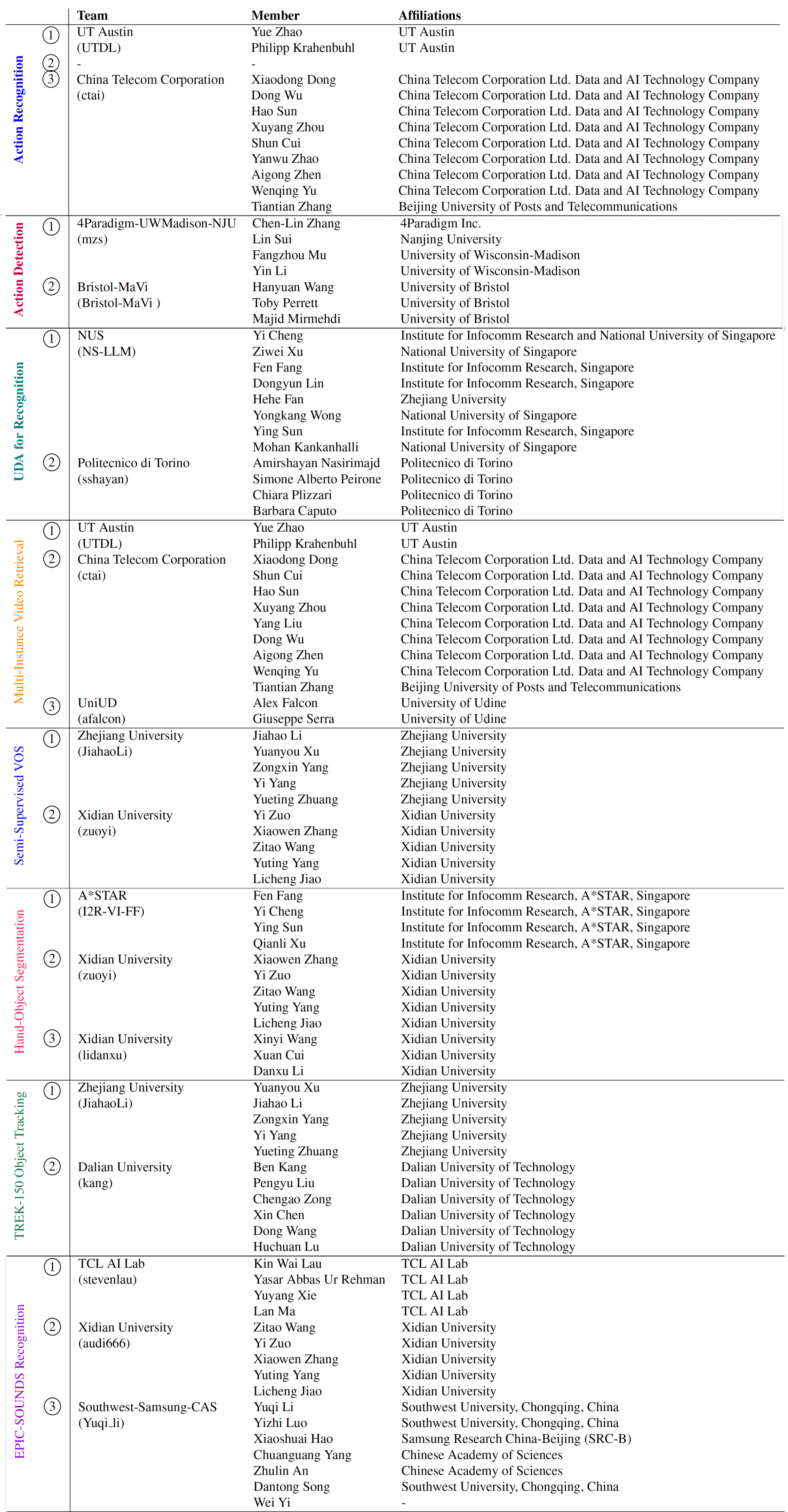
EPIC-KITCHENS-100 Stats and Figures
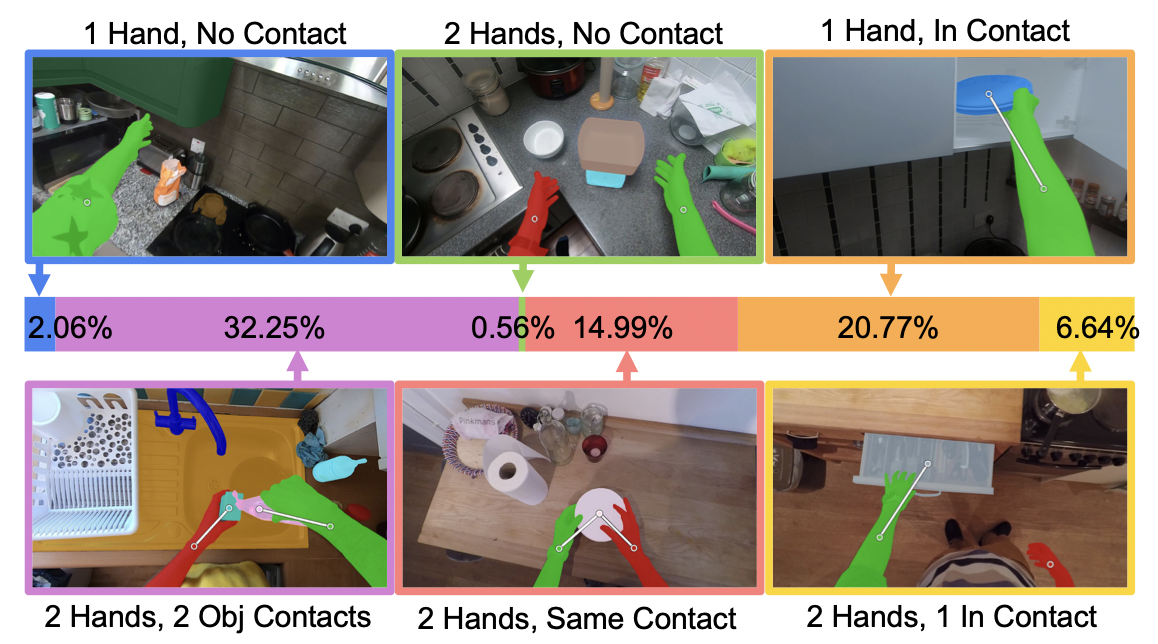
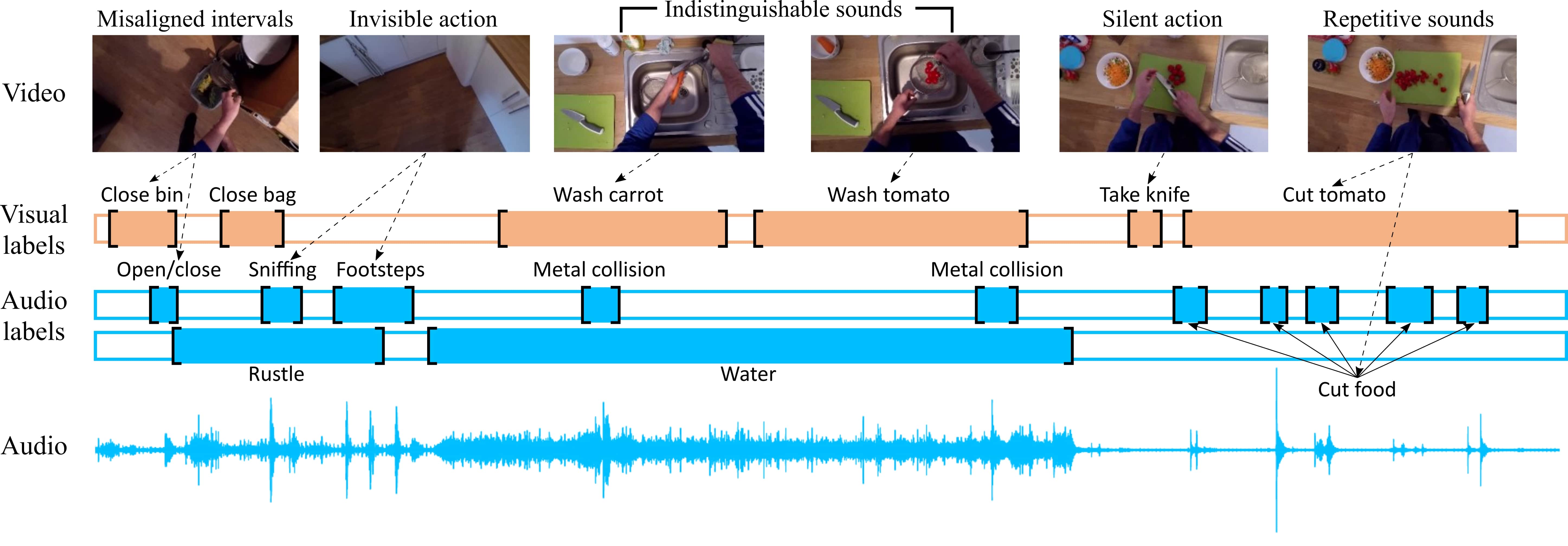
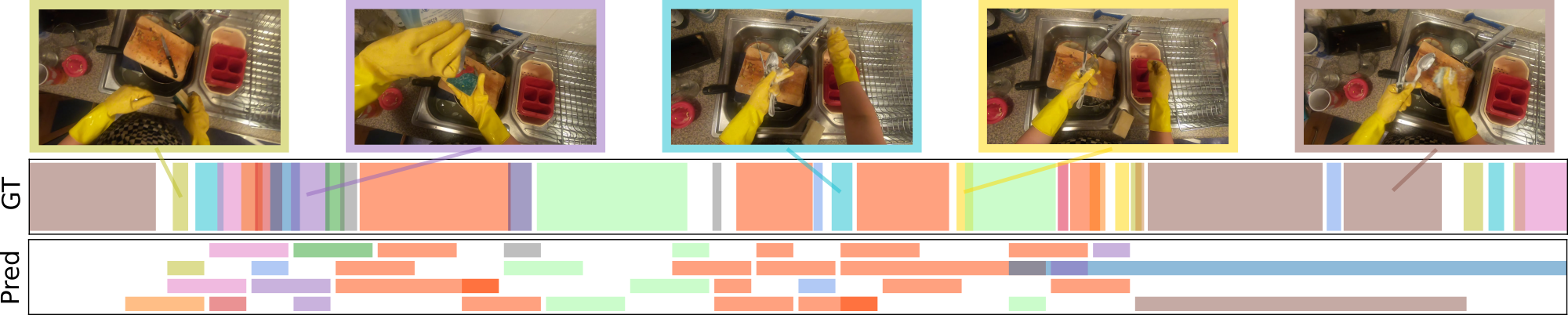
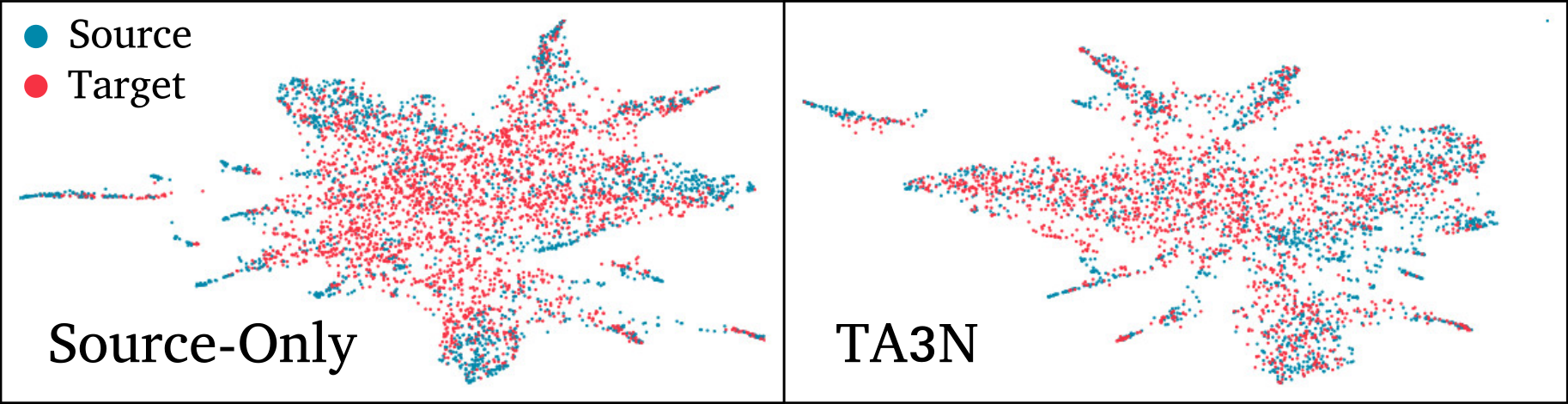
Some graphical representations of our dataset and annotations
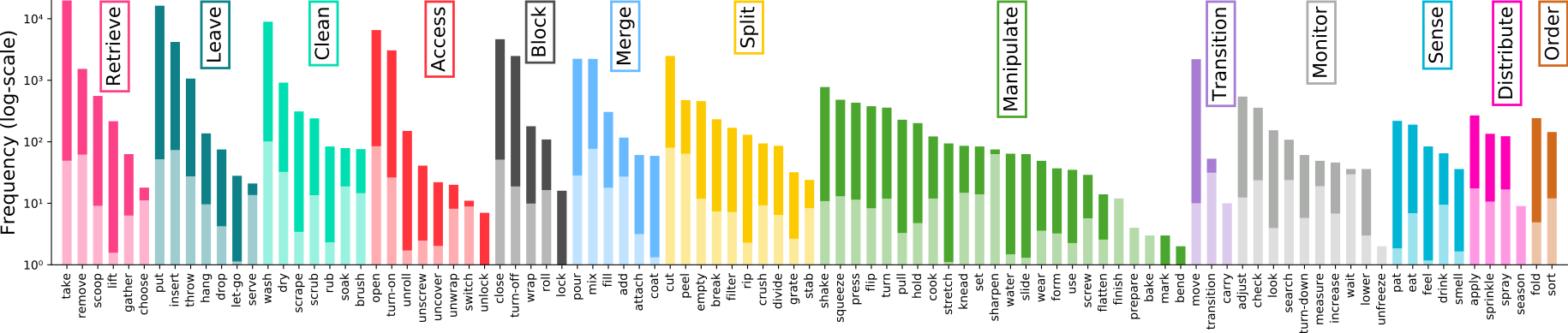
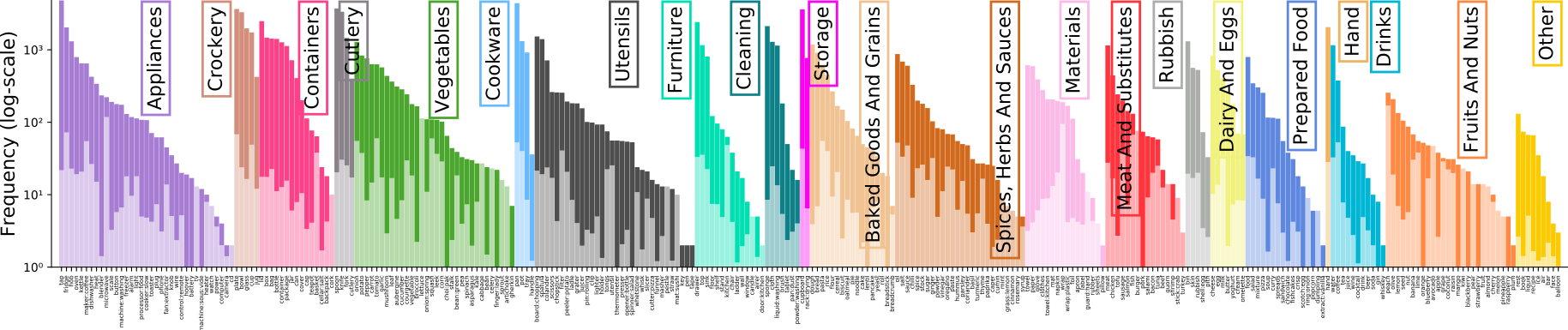
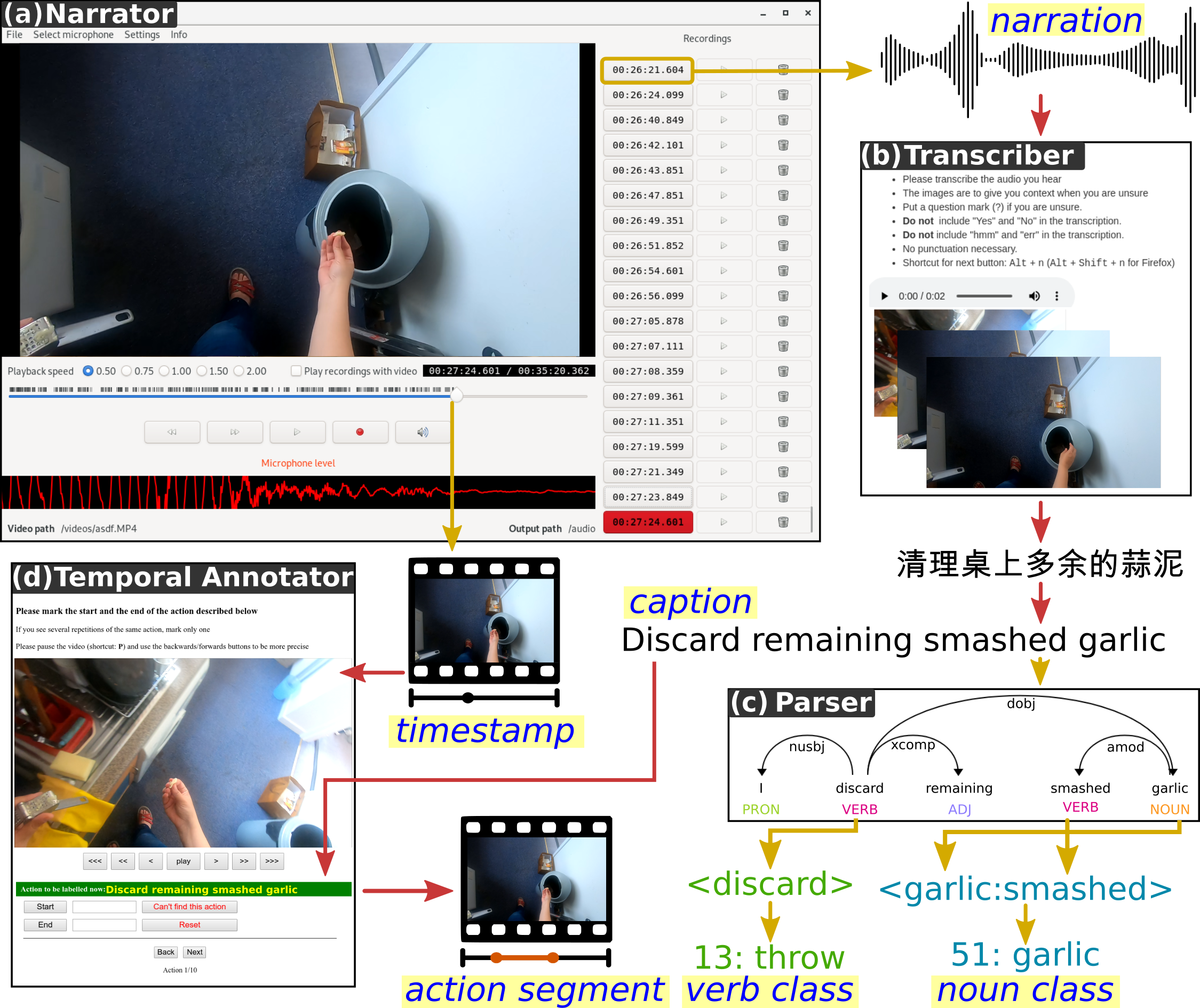
Annotation Pipeline

The large-scale dataset in first-person (egocentric) vision; multi-faceted, audio-visual, non-scripted recordings in native environments - i.e. the wearers' homes, capturing all daily activities in the kitchen over multiple days. Annotations are collected using a novel 'Pause-and-Talk' narration interface.
Erratum [Important]: We have recently detected an error in our pre-extracted RGB and Optical flow frames for two videos in our dataset. This does not affect the videos themselves or any of the annotations in this github. However, if you've been using our pre-extracted frames, you can fix the error at your end by following the instructions in this link.
Extended Sequences (+RGB Frames, Flow Frames, Gyroscope + accelerometer data): Available at Data.Bris servers (740GB zipped) or via Academic Torrents
Original Sequences (+RGB and Flow Frames): Available at Data.Bris servers (1.1TB zipped) or via Academic Torrents
Automatic annotations (masks, hands and objects): Available for download at Data.Bris server (10 GB). We also have two Repos that will allow you to visualise and utilise these automatic annotations for hand-objects as well as masks.
We also offer a python script to download various parts of the dataset
All action segment annotations (Train/Val/Test) for all challenges are available at EPIC-KITCHENS-100-annotations repo
All masks/segmentation annotations are available from VISOR webpage
Audio-only annotations are available from EPIC-SOUNDS webpage
Code to visualise and utilise automatic annotations is available for both object masks and hand-object detections.
The EPIC Narrator, used to collect narrations for EPIC-KITCHENS-100 is open-sourced at EPIC-Narrator repo
Cite our IJCV paper (Open Access 2021 - Published 2022): PDF or Arxiv:
@ARTICLE{Damen2022RESCALING,
title={Rescaling Egocentric Vision: Collection, Pipeline and Challenges for EPIC-KITCHENS-100},
author={Damen, Dima and Doughty, Hazel and Farinella, Giovanni Maria and Furnari, Antonino
and Ma, Jian and Kazakos, Evangelos and Moltisanti, Davide and Munro, Jonathan
and Perrett, Toby and Price, Will and Wray, Michael},
journal = {International Journal of Computer Vision (IJCV)},
year = {2022},
volume = {130},
pages = {33–55},
Url = {https://doi.org/10.1007/s11263-021-01531-2}
} Additionally, cite the original paper (available now on Arxiv and the CVF):
@INPROCEEDINGS{Damen2018EPICKITCHENS,
title={Scaling Egocentric Vision: The EPIC-KITCHENS Dataset},
author={Damen, Dima and Doughty, Hazel and Farinella, Giovanni Maria and Fidler, Sanja and
Furnari, Antonino and Kazakos, Evangelos and Moltisanti, Davide and Munro, Jonathan
and Perrett, Toby and Price, Will and Wray, Michael},
booktitle={European Conference on Computer Vision (ECCV)},
year={2018}
} An extended journal paper is avaliable at: (available now on IEEE and a preprint on Arxiv and ):
@ARTICLE{Damen2021PAMI,
title={The EPIC-KITCHENS Dataset: Collection, Challenges and Baselines},
author={Damen, Dima and Doughty, Hazel and Farinella, Giovanni Maria and Fidler, Sanja and
Furnari, Antonino and Kazakos, Evangelos and Moltisanti, Davide and Munro, Jonathan
and Perrett, Toby and Price, Will and Wray, Michael},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year={2021},
volume={43},
number={11},
pages={4125-4141},
doi={10.1109/TPAMI.2020.2991965}
} EPIC-KITCHENS-55 and EPIC-KITCHENS-100 were collected as a tool for research in computer vision. The dataset may have unintended biases (including those of a societal, gender or racial nature).

All datasets and benchmarks on this page are copyright by us and published under the Creative Commons Attribution-NonCommercial 4.0 International License. This means that you must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use. You may not use the material for commercial purposes.
For commercial licenses of EPIC-KITCHENS and any of its annotations, email us at uob-epic-kitchens@bristol.ac.uk
The nine challenges below and their test sets and evaluation servers are available via CodaLab. The leaderboards will decide the winners for each individual challenge. For each challenge, the CodaLab server page details submission format and evaluation metrics.
This year, we offer four new challenges in: Semi-Supervised Video Object Segmentation using the VISOR annotations, Hand-object-segmentations using the VISOR annotations, single-object tracking and audio-based action recognition using the epic-sounds dataset.
To enter any of the nine competitions, you need to register an account for that challenge using a valid institute (university/company) email address. To enable your account, fill this form with your team's details. A single registration per research team is allowed. We perform a manual check for each submission, and expect to accept registrations within 2 working days.
For all challenges, the maximum submissions per day is limited to 1, and the overall maximum number of submissions per team is limited to 50 overall, submitted once a day. This includes any failed submissions due to formats - please do not contact us to ask for increasing this limit.
To submit your results, follow the JSON submission format, upload your results and give time for the evaluation to complete (in the order of several minutes). Note our new rules on declaring the supervision level, given our proposed scale, for each submission. After the evaluation is complete, the results automatically appear on the public leaderboards but you are allowed to withdraw these at any point in time.
For the Semi-Supervised VOS challenge, an additional step is required by submitting the model/code using a Docker. Please refer to this challenge's section for more details.
To participate in the challenge, you need to have your results on the public leaderboard, along with an informative team name (that represents your institute or the collection of institutes participating in the work), as well as brief information on your method. You are also required to submit a report on your method (in the form of 2-6 pages) to the EPIC@CVPR workshop by June 6th, detailing your entry's technical details.
To submit your technical report, use the CVPR 2023 camera ready author kit (no blind submission), and submit a report of 2-6 pages inclusive of any references to the EPIC@CVPR2023 CMT3 website (Link for CMT). Please select the track "EPIC-Kitchens 2023 Challenges - Technical Papers" when submitting your pdf. These technical reports will be combined into an overall report of the EPIC-Kitchens challenges.
Make the most of the starter packs available with the challenges, and should you have any questions, please use our info email uob-epic-kitchens@bristol.ac.uk
This challenge uses the newly published VISOR annotations.
Task.
Given a sub-sequence of frames with M object masks in the first frame, the goal is to segment these through the remaining frames. Other objects not present in the first frame of the sub-sequence are excluded from this benchmark. Note that any of the M objects can be occluded or out of view, and can reappear during the subsequene.
Validation Submission Phase. Between Jan and end of March, interested parties can submit their results on the validation set to the leaderboard. Successful top submissions will be invited to evaluate on the hidden Test Set in the next phase
Test Submission (Final Test). Interested participants who have already registered their interest through submitting their models to the Validation Server are now invited to evaluate their models on the test set. As we do not plan to release the first frame annotations for the test set, to avoid overfitting, you are asked to submit the trained models for inference through a Docker that will be evaluated at our end. We have now announced Instructions to evaluate on the test set. You can now contact us at any point to try your model on the test server (Open for submissions until 1st of June). Winners of the challenge are only decided based on the performance on the hidden test set
Evaluation metrics. Average of J-Decay and F-Recall as with other video object segmentation benchmarks.
Task.
Segment hands and the corresponding objects being interacted with in images.
Training input. A set of images with hand masks, object masks and hand-object relations.
Testing input. A set of images in the test set.
Splits. VISOR Train and validation for training, evaluated on the VISOR test split.
Evaluation metrics. Mean Average Precision (mAP) @ IOU 0.1 to 0.5.
Lead: Dandan Shan (University of Michigan), Richard Higgins (University of Michigan) and David Fouhey (University of Michigan)
Task.
The challenge requires to track an object instance through a first-person video sequence. The challenge will be carried out on the TREK-150 dataset, a subset of the EPIC-KITCHENS dataset labeled for single object tracking. More information on the dataset and downloads can be found here.
Lead: Matteo Dunnhofer (University of Udine), Antonino Furnari (University of Catania), Giovanni Maria Farinella (University of Catania), Christian Micheloni (University of Udine)
Task. Assign an audio-class label to a trimmed segment, indicating the class of interaction taking place in the video. This uses the EPIC-SOUNDS dataset annotations.
Training input. A set of trimmed audio segments, each annotated with one of 44 class labels.
Testing input. A set of trimmed unlabelled audio segments.
Splits. Train/Val/Test splits are available
here.
Evaluation metrics. Top-1/5 accuracy for audio class, on the target test set, as well as mAC mAP and mAUC for class-balanced metrics.
Leads: Jaesung Huh (University of Oxford), Jacob Chalk (University of Bristol), Evangelos Kazkos (ex- Univ of Bristol), Dima Damen (University of Bristol) and Andrew Zisserman (University of Oxford)
Splits. The dataset is split in train/validation/test sets, with a ratio of roughly 75/10/15.
The action recognition, detection and anticipation challenges use all the splits.
The unsupservised domain adaptation and action retrieval challenges use different splits as detailed below.
You can download all the necessary annotations here.
You can find more details about the splits in our paper.
Evaluation. All challenges are evaluated considering all segments in the Test split.
The action recognition and anticipation challenges are additionally evaluated considering unseen participants and tail classes. These are automatically evaluated in the scripts and you do not need to do anything specific to report these.
Unseen participants. The validation and test sets contain participants that are not present in the train set.
There are 2 unseen participants in the validation set, and another 3 participants in the test set.
The corresponding action segments are 1,065 and 4,110 respectively.
Tail classes. These are the set of smallest classes whose instances account for 20% of the total number of instances in
training. A tail action class contains either a tail verb class or a tail noun class.
Task.
Assign a (verb, noun) label to a trimmed segment.
Training input (strong supervision). A set of trimmed action segments, each annotated with a (verb, noun) label.
Training input (weak supervision). A set of untrimmed videos, each annotated with a list of (timestamp, verb, noun) labels.
Note that for each action you are given a single, roughly aligned timestamp, i.e. one timestamp located
around the action. Timestamps may be located over background frames or frames belonging to another action.
Testing input. A set of trimmed unlabelled action segments.
Splits. Train and validation for training, evaluated on the test split.
Evaluation metrics. Top-1/5 accuracy for verb, noun and action (verb+noun), calculated for all segments as well as
unseen participants and tail classes.

Task.
Detect the start and the end of each action in an untrimmed video. Assign a (verb, noun) label to each
detected segment.
Training input. A set of trimmed action segments, each annotated with a (verb, noun) label.
Testing input. A set of untrimmed videos. Important: You are not allowed to use the knowledge of trimmed segments in the test set when reporting for this challenge.
Splits. Train and validation for training, evaluated on the test split.
Evaluation metrics. Mean Average Precision (mAP) @ IOU 0.1 to 0.5.
Task.
Predict the (verb, noun) label of a future action observing a segment preceding its occurrence.
Training input. A set of trimmed action segments, each annotated with a (verb, noun) label.
Testing input. During testing you are allowed to observe a segment that ends at least one second before
the start of the action you are testing on.
Splits. Train and validation for training, evaluated on the test split.
Evaluation metrics. Top-5 recall averaged for all classes, as defined here,
calculated for all segments as well as unseen participants and tail classes.

Task. Assign a (verb, noun) label to a trimmed segment, following the Unsupervised Domain Adaptation paradigm:
a labelled source domain is used for training, and the model needs to adapt to an unlabelled target domain.
Training input. A set of trimmed action segments, each annotated with a (verb, noun) label.
Testing input. A set of trimmed unlabelled action segments.
Splits. Videos recorded in 2018 (EPIC-KITCHENS-55) constitute the source domain,
while videos recorded for EPIC-KITCHENS-100's extension constitute the unlabelled target domain.
This challenge uses custom train/validation/test splits, which you can find
here.
Evaluation metrics. Top-1/5 accuracy for verb, noun and action (verb+noun), on the target test set.
Tasks. Video to text: given a query video segment, rank captions such that those with a higher rank are
more semantically relevant to the action in the query video segment.
Text to video: given a query caption, rank video segments such that those with a higher rank are more semantically relevant
to the query caption.
Training input. A set of trimmed action segments, each annotated with a caption.
Captions correspond to the narration in English from which the action segment was obtained.
Testing input. A set of trimmed action segments with captions. Important: You are not allowed to use the known correspondence in the Test set
Splits. This challenge has its own custom splits, available here.
Evaluation metrics. normalised Discounted Cumulative Gain (nDCG) and Mean Average Precision (mAP).
You can find more details in our paper.

We are a group of researchers working in computer vision from the University of Bristol and University of Catania. The original dataset was collected in collaboration with Sanja Fidler, University of Toronto


We are hosting additional challenges for 2023 led by:
The work on extending EPIC-KITCHENS was supported by the following research grants