EPIC-Kitchens Stats
Some graphical representations of our dataset and annotations
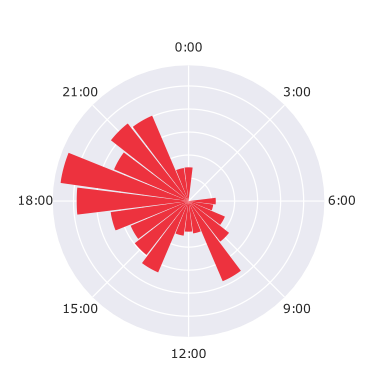
Time Of Day
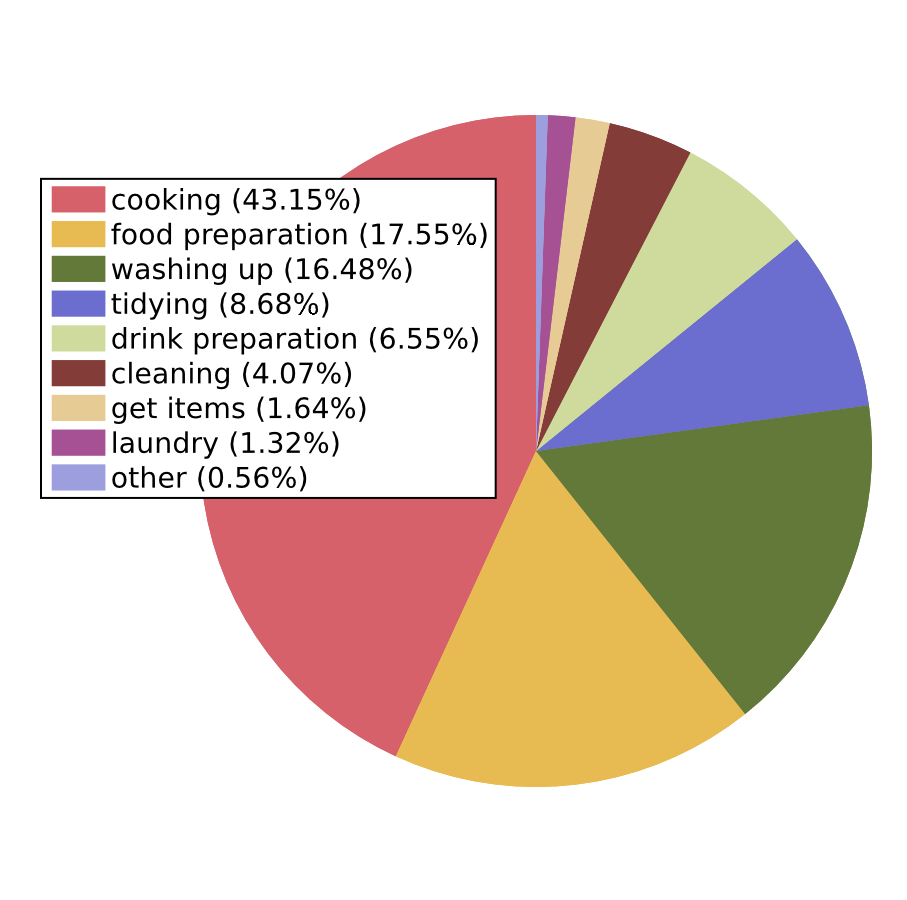
Activities

Wordle of annotations
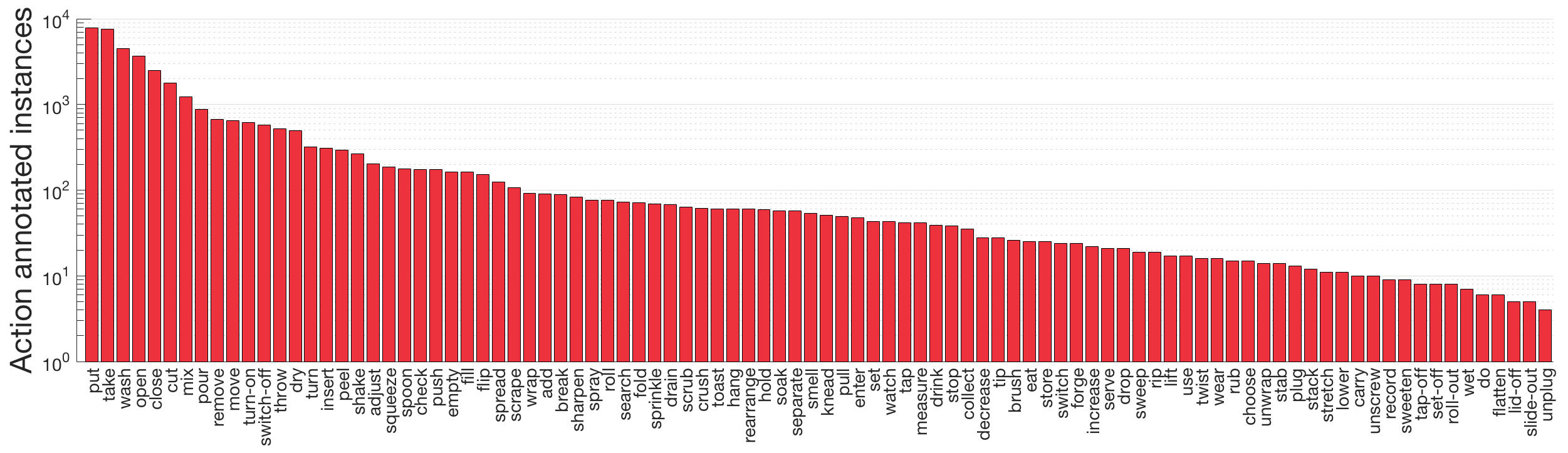
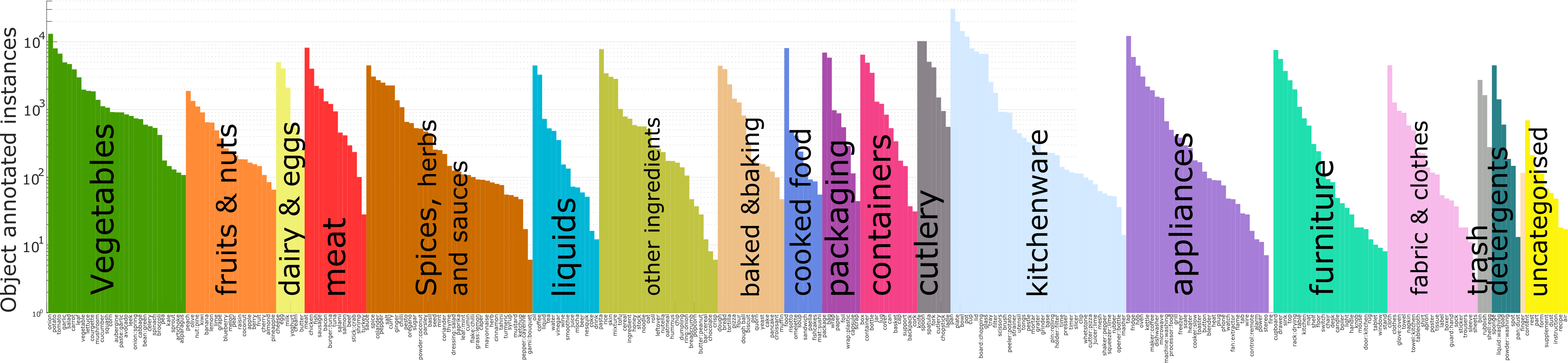
The largest dataset in first-person (egocentric) vision; multi-faceted non-scripted recordings in native environments - i.e. the wearers' homes, capturing all daily activities in the kitchen over multiple days. Annotations are collected using a novel `live' audio commentary approach.
Stay tuned with updates on epic-kitchens2018, as well as EPIC workshop series by joining the epic-community mailing list send an email to: sympa@sympa.bristol.ac.uk with the subject subscribe epic-community and a blank message body.
Sequences: Available at Data.Bris servers (1TB zipped)
To download parts of the dataset, we provide three scripts for downloading the
Cite the following paper (available now on Arxiv and the CVF):
@INPROCEEDINGS{Damen2018EPICKITCHENS,
title={Scaling Egocentric Vision: The EPIC-KITCHENS Dataset},
author={Damen, Dima and Doughty, Hazel and Farinella, Giovanni Maria and Fidler, Sanja and
Furnari, Antonino and Kazakos, Evangelos and Moltisanti, Davide and Munro, Jonathan
and Perrett, Toby and Price, Will and Wray, Michael},
booktitle={European Conference on Computer Vision (ECCV)},
year={2018}
} 
All datasets and benchmarks on this page are copyright by us and published under the Creative Commons Attribution-NonCommercial 4.0 International License. This means that you must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use. You may not use the material for commercial purposes.
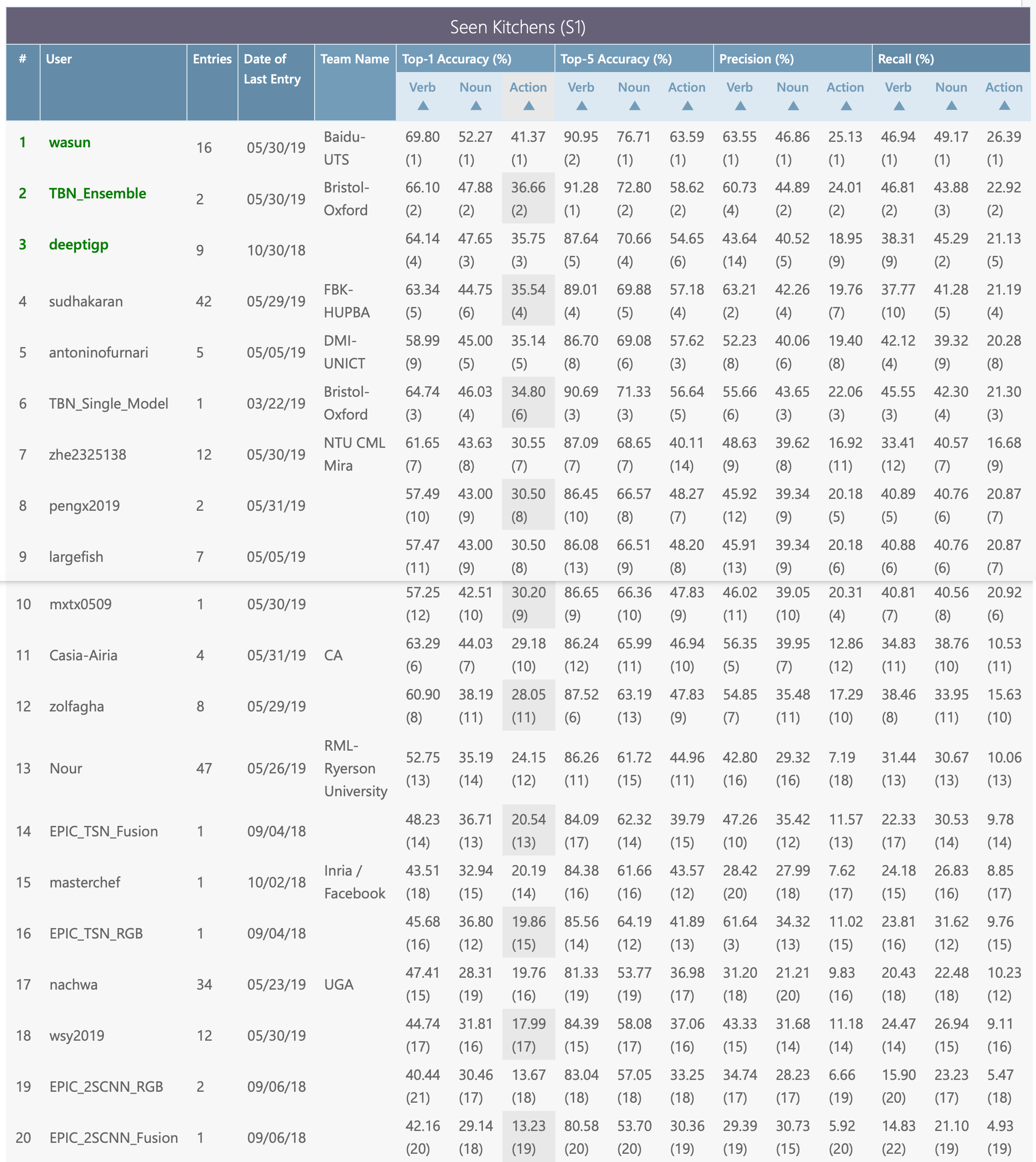
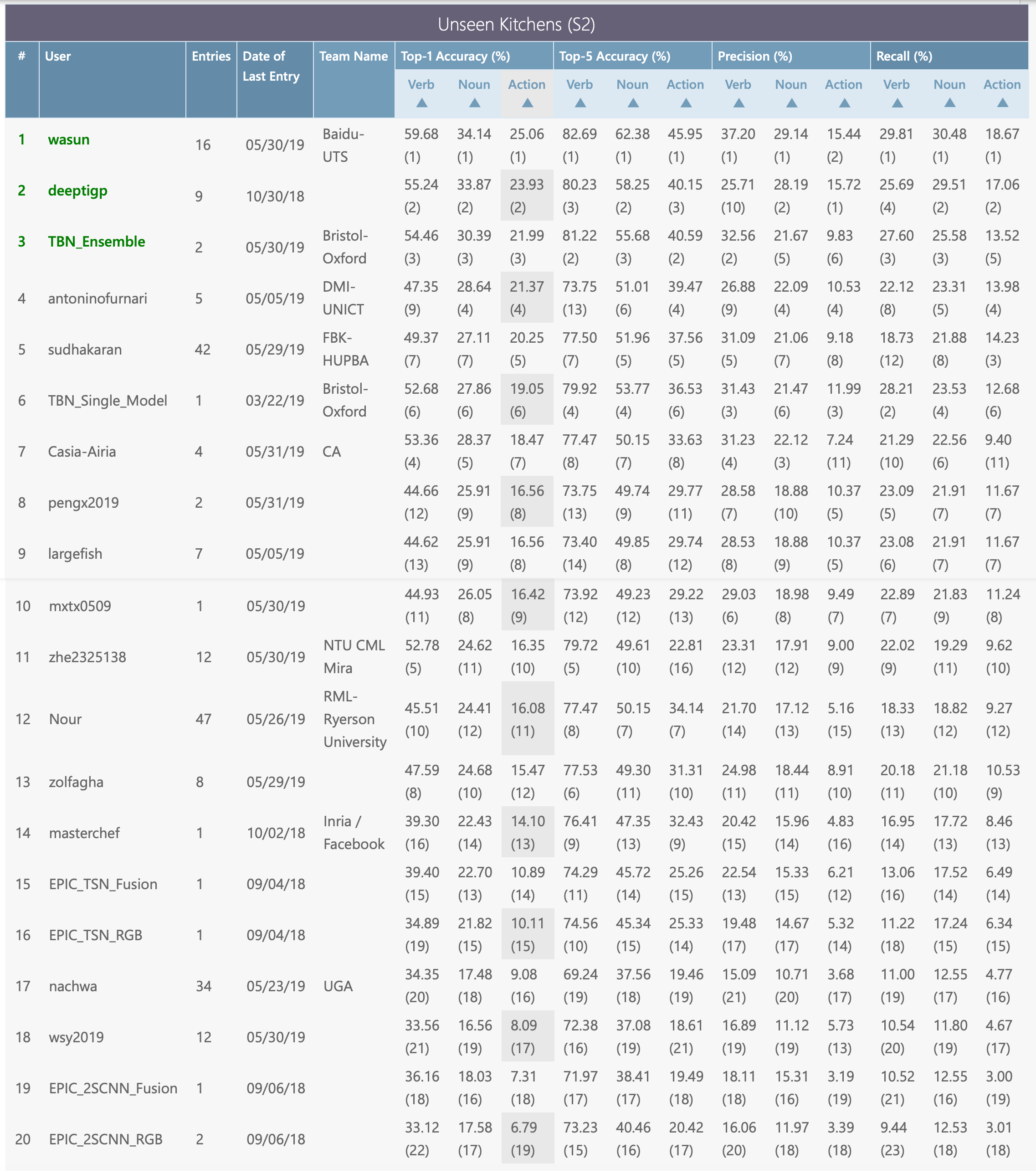
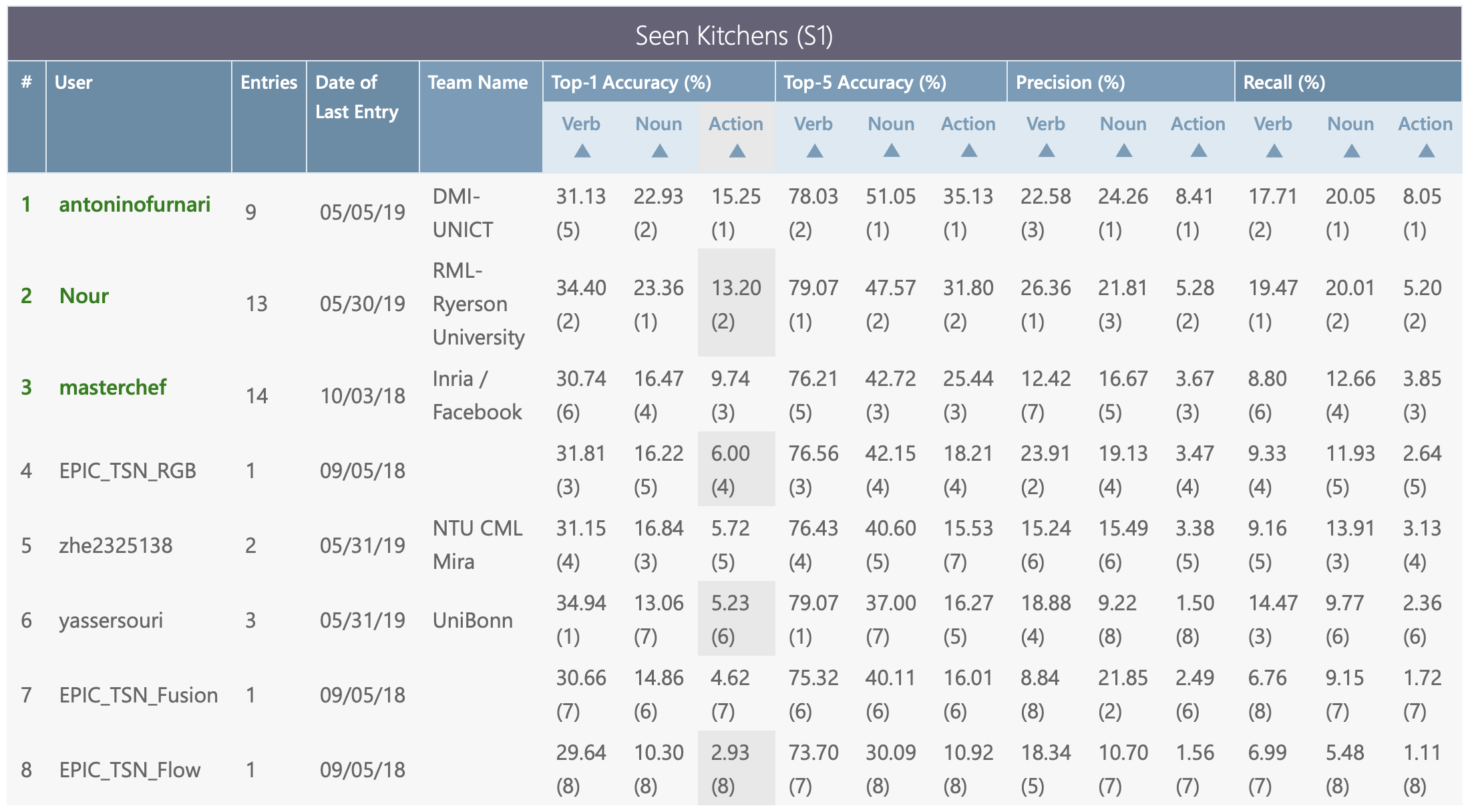
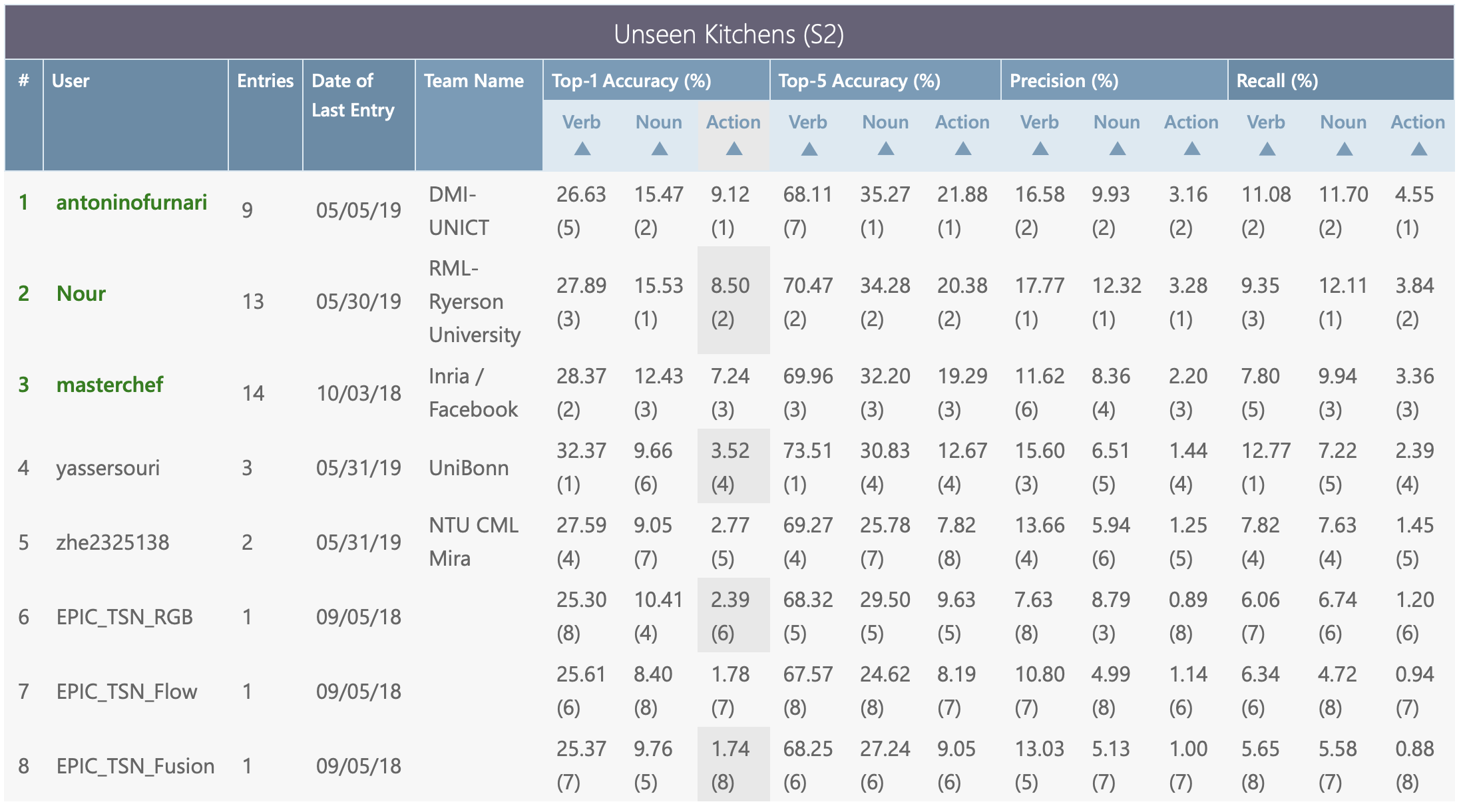
The three challenges below and their test sets and evaluation servers are available via CodaLab. The leaderboards will decide the winners for each individual challenge. When comparing to state of the art (i.e. in papers), results should be reported on bot test sets (S1 and S2) via submitting your predictions to the evaluation server.
For each challenge, the CodaLab server page details submission format and evaluation metrics. To enter any of the three competitions, you need to register an account for that challenge using a valid institute (university/company) email address. A single registration per research team is allowed. For all challenges the maximum sumissions per day is limited to 1.
To submit your results, follow the JSON submission format, upload your results and give time for the evaluation to complete (in the order of several minutes). After the evaluation is complete, the results automatically appear on the public leaderboards but you are allowed to withdraw these at any point in time.
To participate in the challenge, you need to have your results on the public leaderboard, along with an informative team name (that represents your institute or the collection of institutes participating in the work), as well as brief information on your method. You are also required to submit a report on your method (in the form of 2-6 pages) to the EPIC@CVPR workshop by June 7th, detailing your entry's technical details.
To submit your technical report, use the CVPR 2019 camera ready author kit (no blind submission), and submit a report of 2-6 pages inclusive of any references to the EPIC@CVPR2019 CMT3 website. Please select the track "EPIC-Kitchens 2019 Challenges - Technical Papers" when submitting your pdf. These technical reports will be combined into an overall report of the EPIC-Kitchens challenges.
Make the most of the starter packs available with the challenges, and should you have any questions, please use our info email uob-epic-kitchens2018@bristol.ac.uk
Given a trimmed action segment, the challenge is to classify the segment into its action class composed of the pair of verb and noun classes. To participate in this challenge, predictions for all segments in the seen (S1) and unseen (S2) test sets should be provided. For each test segment we require the confidence scores for each verb and noun class.
Submit your results on CodaLab website

Given an anticipation time, set to 1s before the action starts, the challenge is to classify the future action into its action class composed of the pair of verb and noun classes. To participate in this challenge, predictions for all segments in the seen (S1) and unseen (S2) test sets should be provided. For each test segment we require the confidence scores for each verb and noun class.
Submit your results on CodaLab website

This challenge focuses on object detection and localisation. Note that our annotations only capture the ‘active’ objects pre-, during- and post- interaction. To participate in the challenge bounding box predictions with confidence scores should be submitted for sampled frames from the seen (S1) and unseen (S2) test sets.
Submit your results on CodaLab website

We are a group of researchers working in computer vision from the University of Bristol, University of Toronto, and University of Catania.






The dataset is sponsored by: